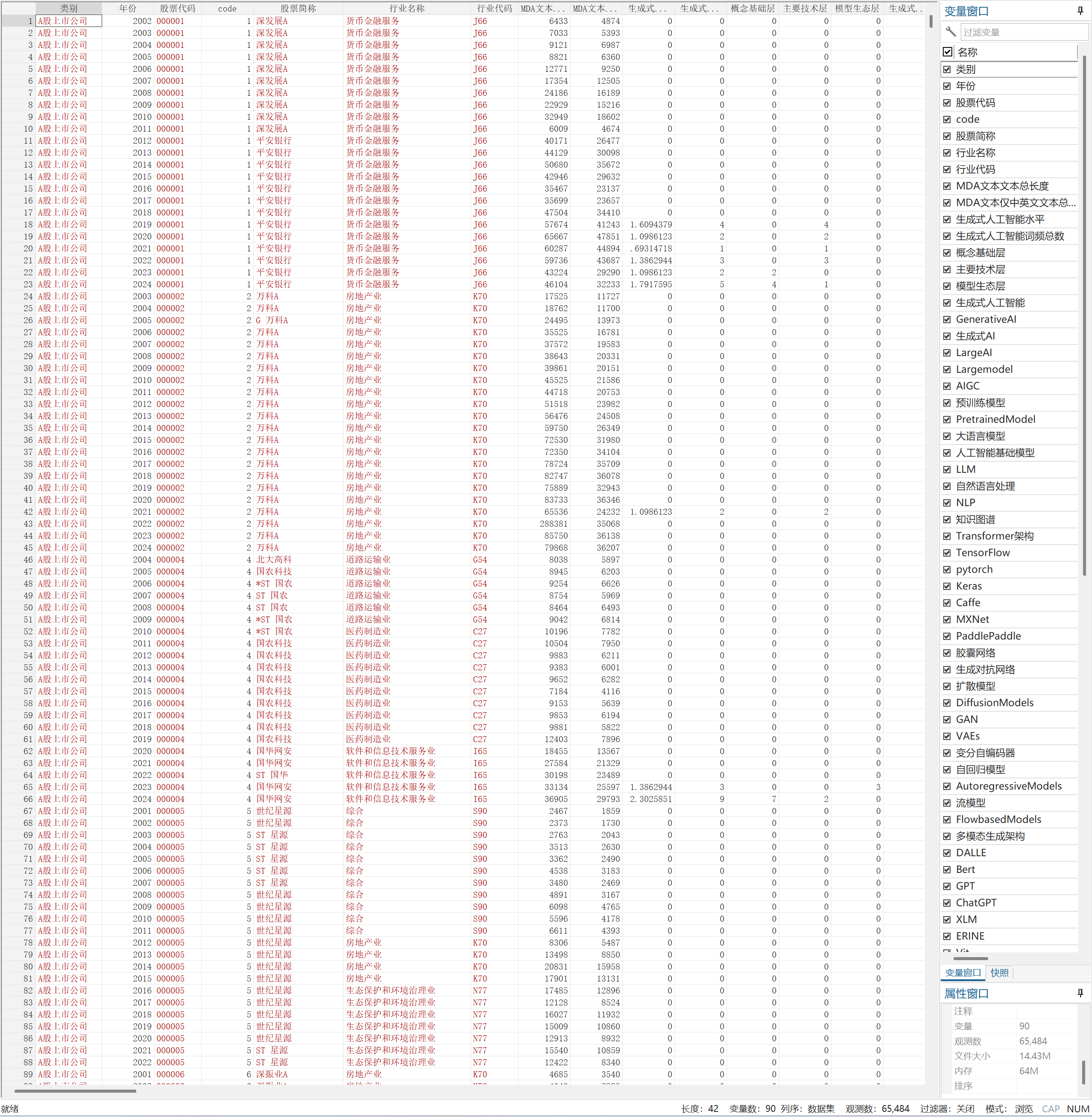
生成式人工智能水平-MD&A词频统计(2001-2024年)
高级会员
| 来源:上市公司“管理层讨论与分析”
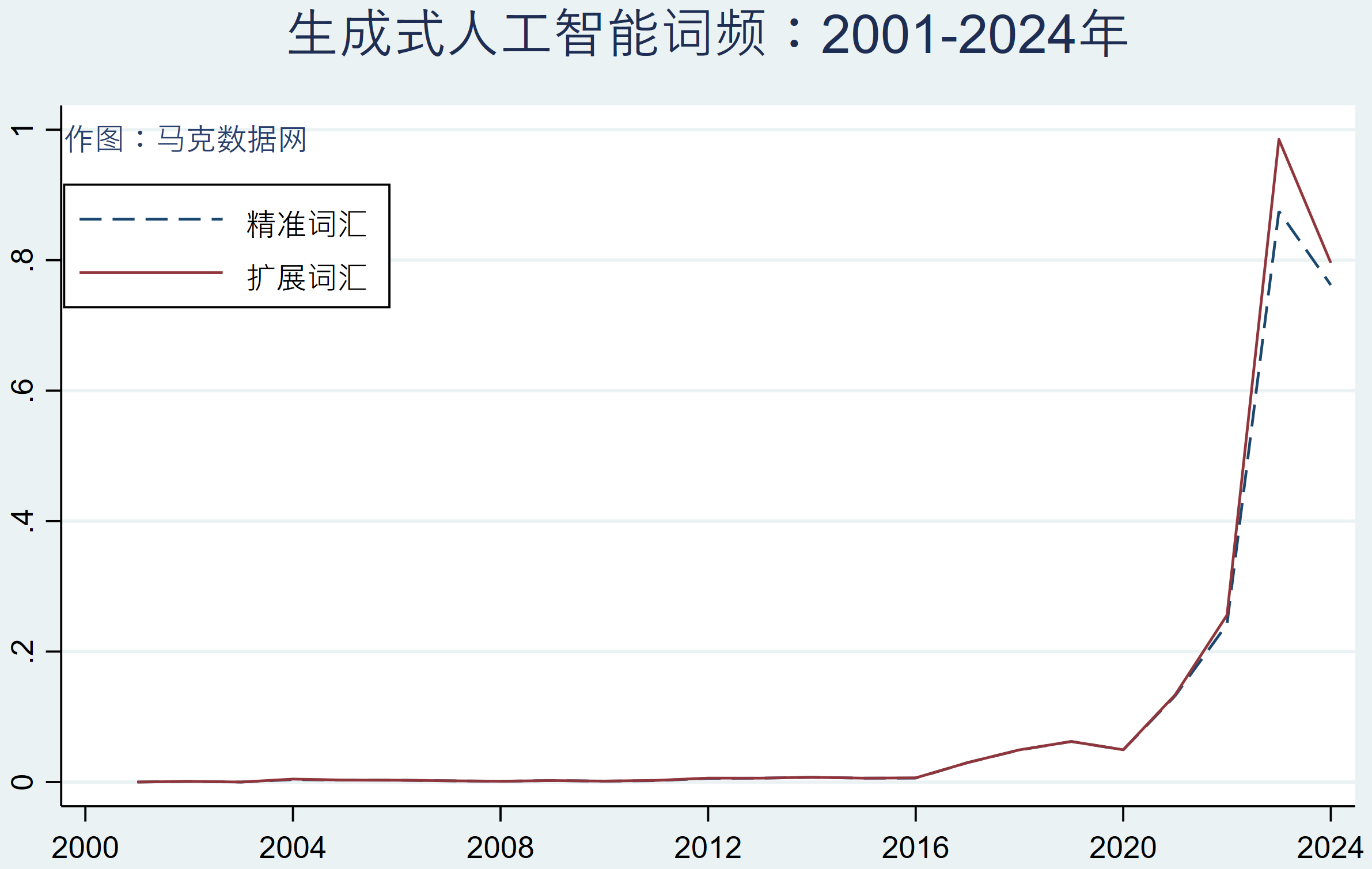
本期附赠数据中,进一步用MD&A文本统计生成式人工智能词频
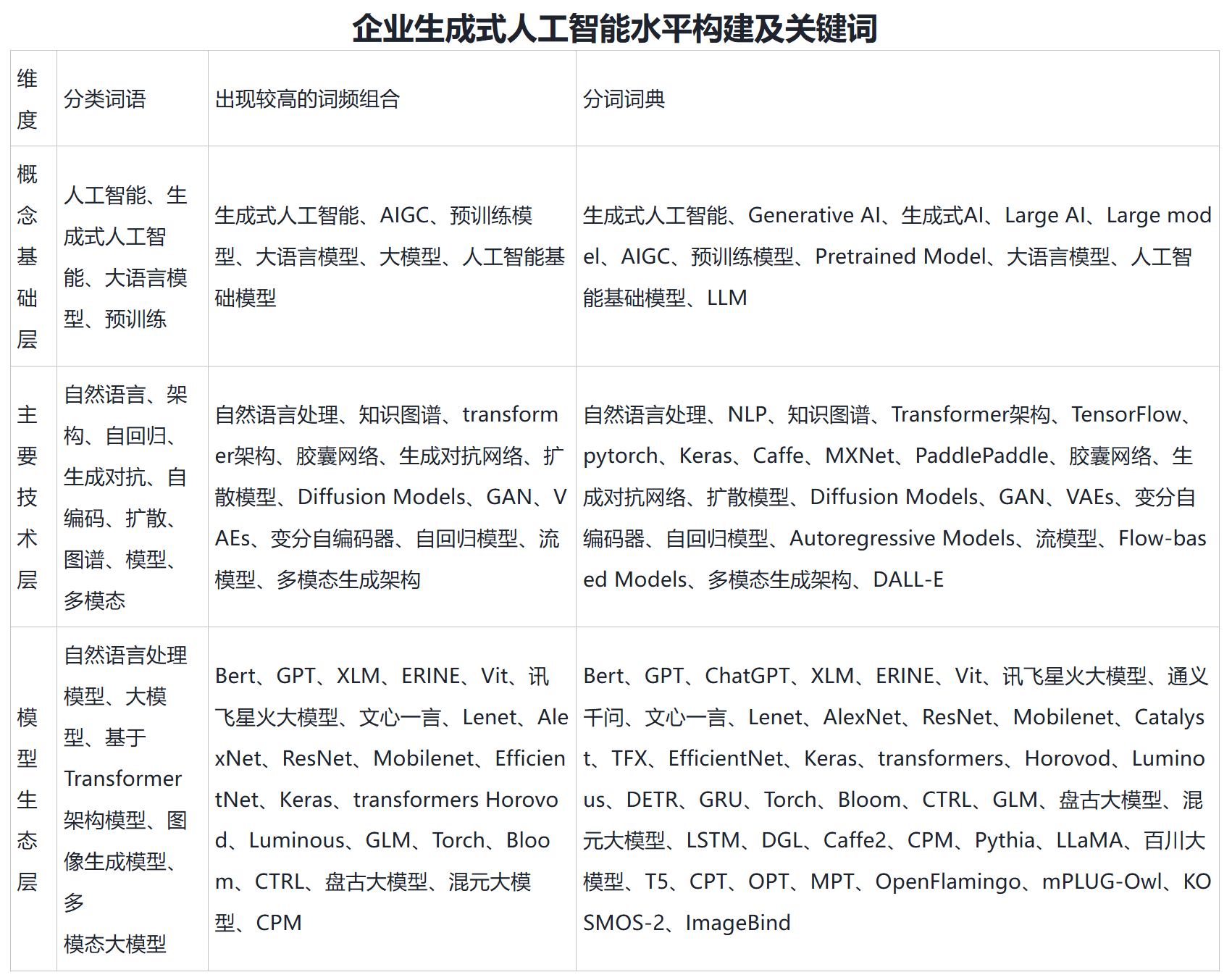
借鉴乔朋华等(2025)《生成式人工智能如何提升制造业企业韧性?》一文中对生成式人工智能文本词频的做法,团队根据上市公司年报MD&A文本内容,对79个生成式人工智能的相关词频进行统计,并计算上市公司生成式人工智能水平,包括精确词汇、扩展词汇两种方式
MD&A文本筛选:2014年及以前主要在“董事会报告”中筛选,2015年主要在“管理层讨论与分析”中筛选,2016-2020年主要从“经营情况讨论与分析”中筛选,2021-2024年主要在“管理层讨论与分析”中提取
相关数据:生成式人工智能词频数据,人工智能词频数据,人工智能招聘数据,管理层讨论与分析文本
一、数据介绍数据名称:生成式人工智能水平-MD&A报告统计
数据范围:A股上市公司
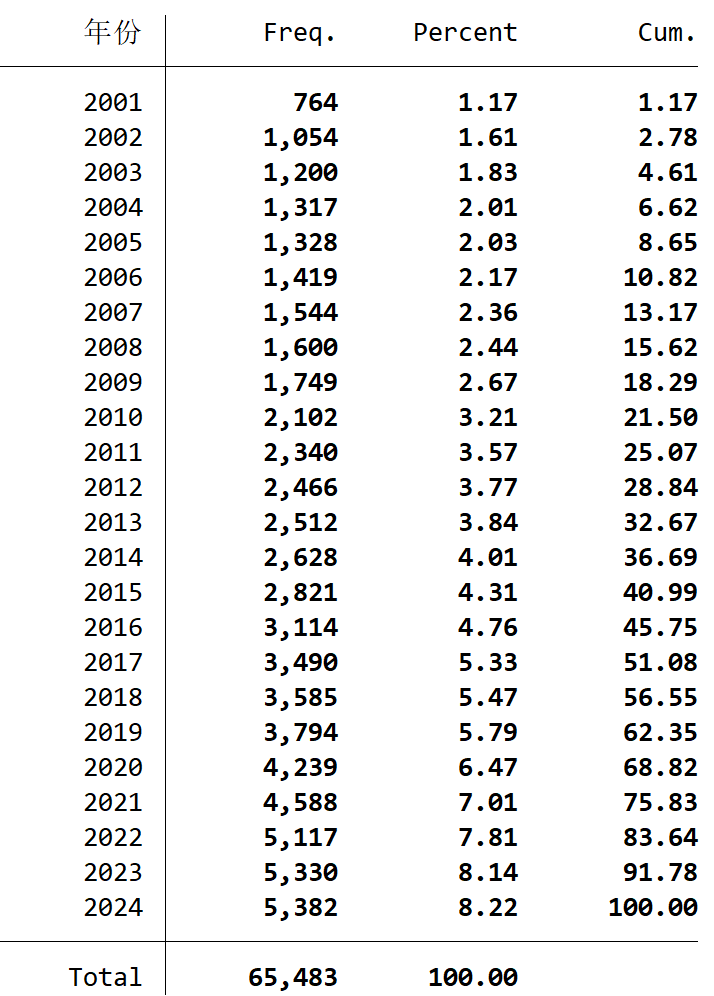
时间范围:2001-2024年
样本数量:65484条,93个变量
数据来源:“管理层讨论与分析”文本
数据整理:马克数据网
更新时间:2025年10月
更多说明:内含生成式人工智能79个词频、精确和扩展词汇两种方式
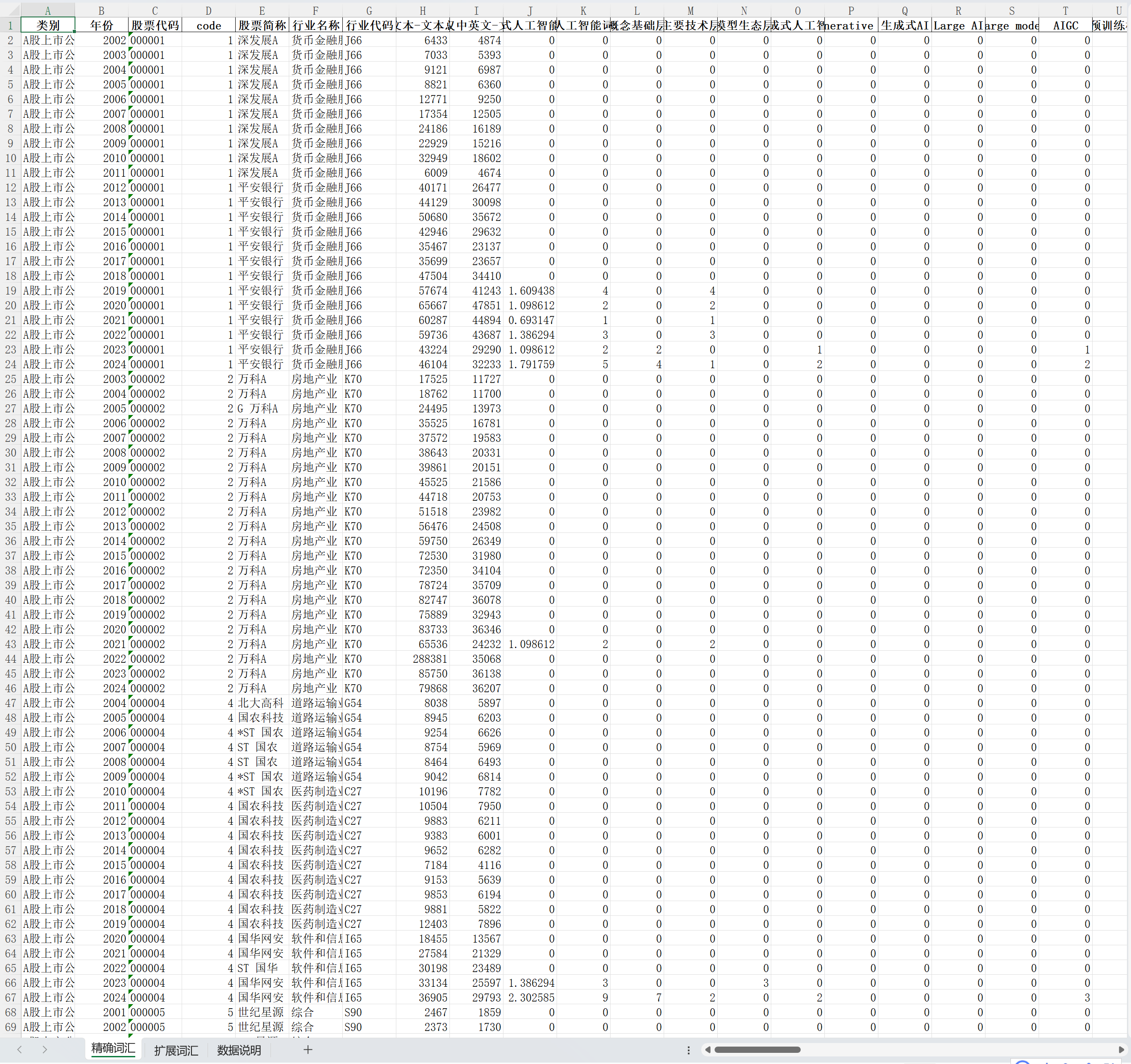
二、数据指标| 类别 | 年份 | 股票代码 |
| code | 股票简称 | 行业名称 |
| 行业代码 | MD&A文本-文本总长度 | MD&A文本仅中英文-文本总长度 |
| 生成式人工智能水平 | 生成式人工智能词频总数 | 概念基础层 |
| 主要技术层 | 模型生态层 | 生成式人工智能 |
| Generative | AI | 生成式AI |
| Large | model | AIGC |
| 预训练模型 | Pretrained | Model |
| 大语言模型 | 人工智能基础模型 | LLM |
| 自然语言处理 | NLP | 知识图谱 |
| Transformer架构 | TensorFlow | pytorch |
| Keras | Caffe | MXNet |
| PaddlePaddle | 胶囊网络 | 生成对抗网络 |
| 扩散模型 | Diffusion | Models |
| GAN | VAEs | 变分自编码器 |
| 自回归模型 | Autoregressive | 流模型 |
| Flow-based | 多模态生成架构 | DALL-E |
| Bert | GPT | ChatGPT |
| XLM | ERINE | Vit |
| 讯飞星火大模型 | 通义千问 | 文心一言 |
| Lenet | AlexNet | ResNet |
| Mobilenet | Catalyst | TFX |
| EfficientNet | transformers | Horovod |
| Luminous | DETR | GRU |
| Torch | Bloom | CTRL |
| GLM | 盘古大模型 | 混元大模型 |
| LSTM | DGL | Caffe2 |
| CPM | Pythia | LLaMA |
| 百川大模型 | T5 | CPT |
| OPT | MPT | OpenFlamingo |
| mPLUG-Owl | KOSMOS-2 | ImageBind |
企业生成式人工智能水平关键词
各年份统计-面板格式
生成式人工智能水平MD&A词频统计-Excel版
生成式人工智能水平MD&A词频统计-Stata版
注:该数据为高级会员-附赠数据,可在底部直接下载数据
该数据需要高级会员以上的权限,
请先登录您的账号: 点击登录