上市公司生成式人工智能-文本词频明细(1998-2024年)
高级会员
| 来源:上市公司年报文本
生成式人工智能是人工智能的一个重要分支,它通过深度学习模型学习文本、图像、音频、代码等数据中的规律,从而具备“创作”能力。生成式AI不仅能撰写文章、绘制图像、编写程序、作曲或生成视频,还能辅助科研、教育、金融、设计等领域实现智能化创新
借鉴乔朋华等(2025)《生成式人工智能如何提升制造业企业韧性?》一文中对生成式人工智能文本词频的做法,采用生成式人工智能关键词在企业年报信息中出现的次数作为企业生成式人工智能水平的代理指标。整理步骤如下:
第一步,整理所有样本企业的上市公司年报并将其转化为纯文本格式
第二步,确定生成式人工智能种子词搜索范围
第三步,根据分词词典使用 python 语言编程对年报文本内容进行分词与文本抓取,统计文中出现的生成式人工智能特征词词数
第四步,对词数加一取自然对数
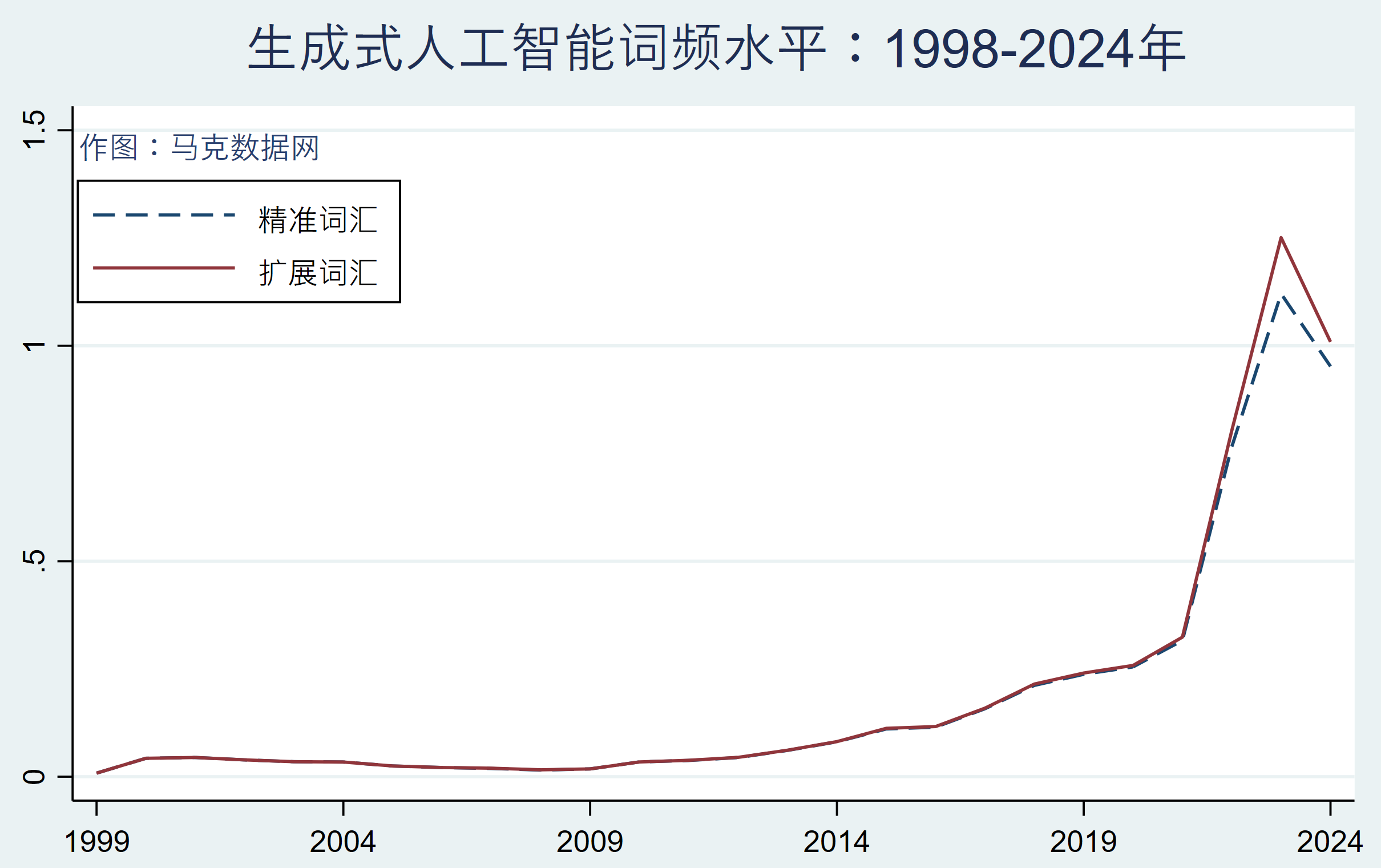
相关数据:上市公司数字化词频数据,人工智能词频数据,上市公司年报原文数据
一、数据介绍数据名称:上市公司生成式人工智能-文本词频明细
数据范围:A股上市公司
时间范围:1998-2024年
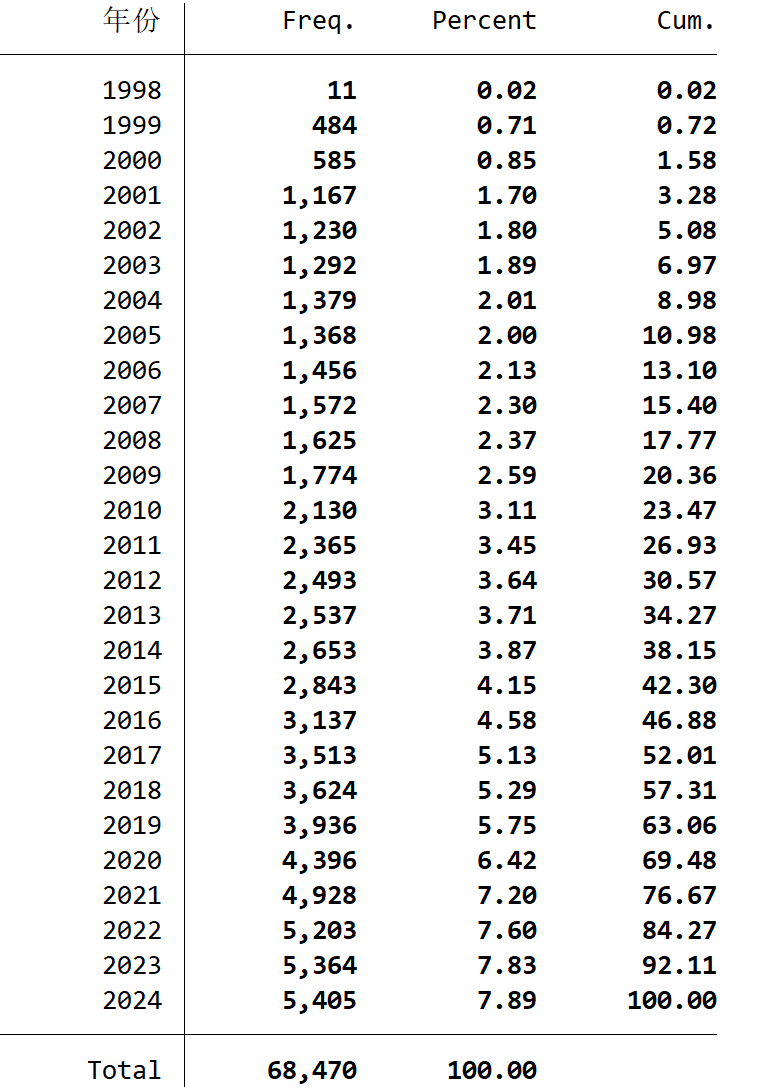
样本数量:68471条
数据来源:上市公司年报
数据整理:马克数据网
更新时间:2025年10月
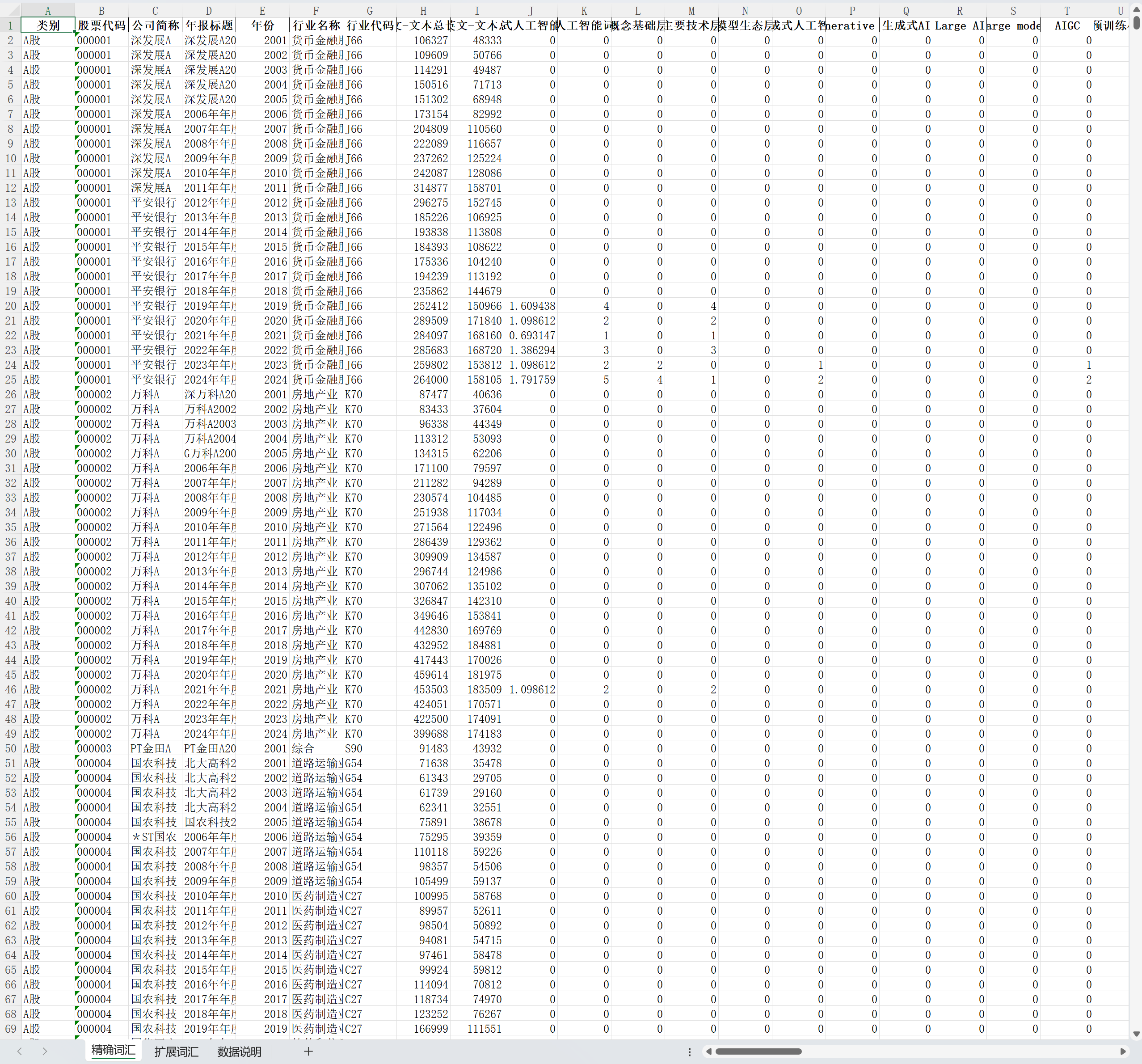
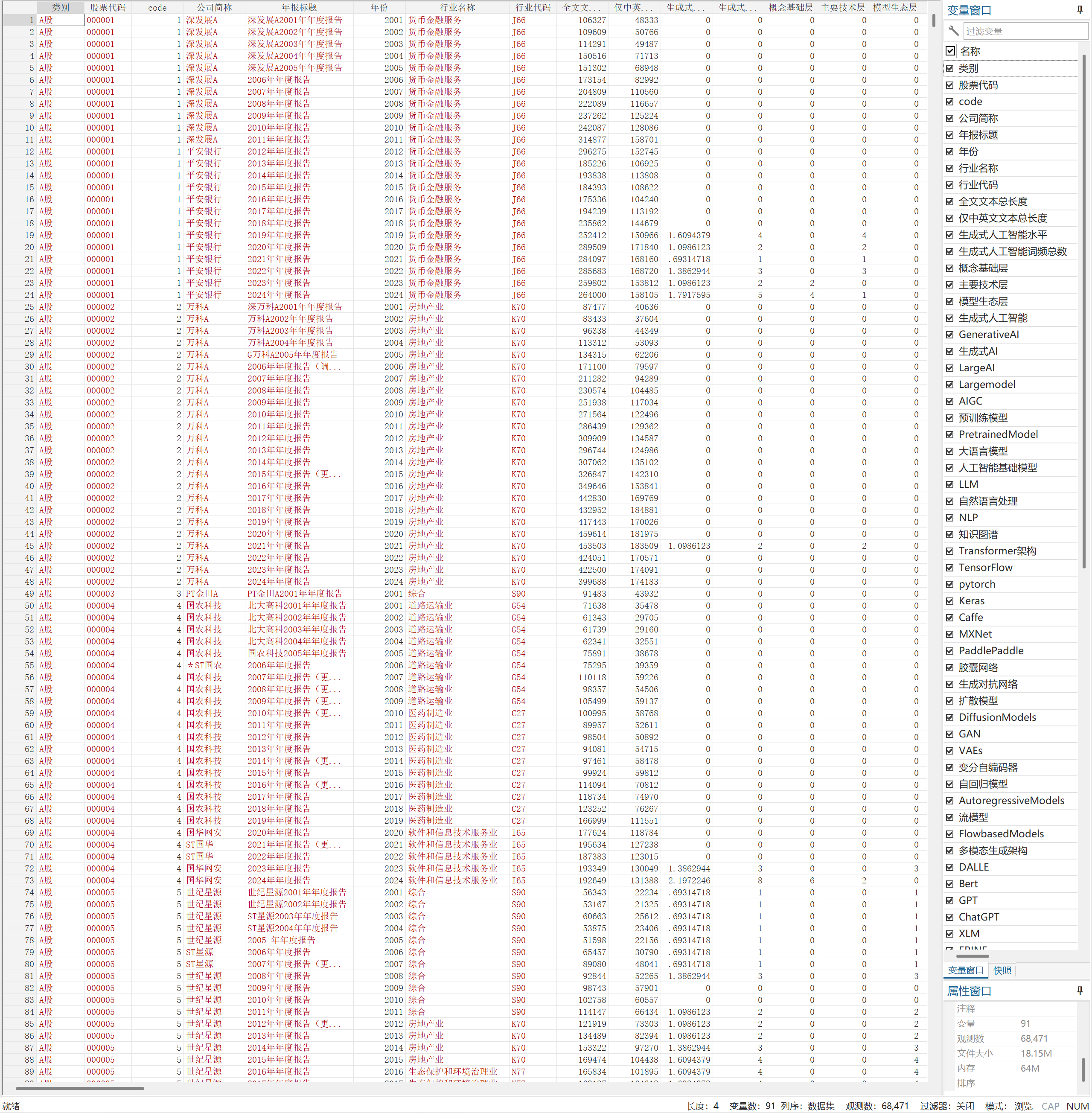
二、数据指标| 类别 | 股票代码 | 公司简称 |
| 年报标题 | 年份 | 行业名称 |
| 行业代码 | 全文-文本总长度 | 仅中英文-文本总长度 |
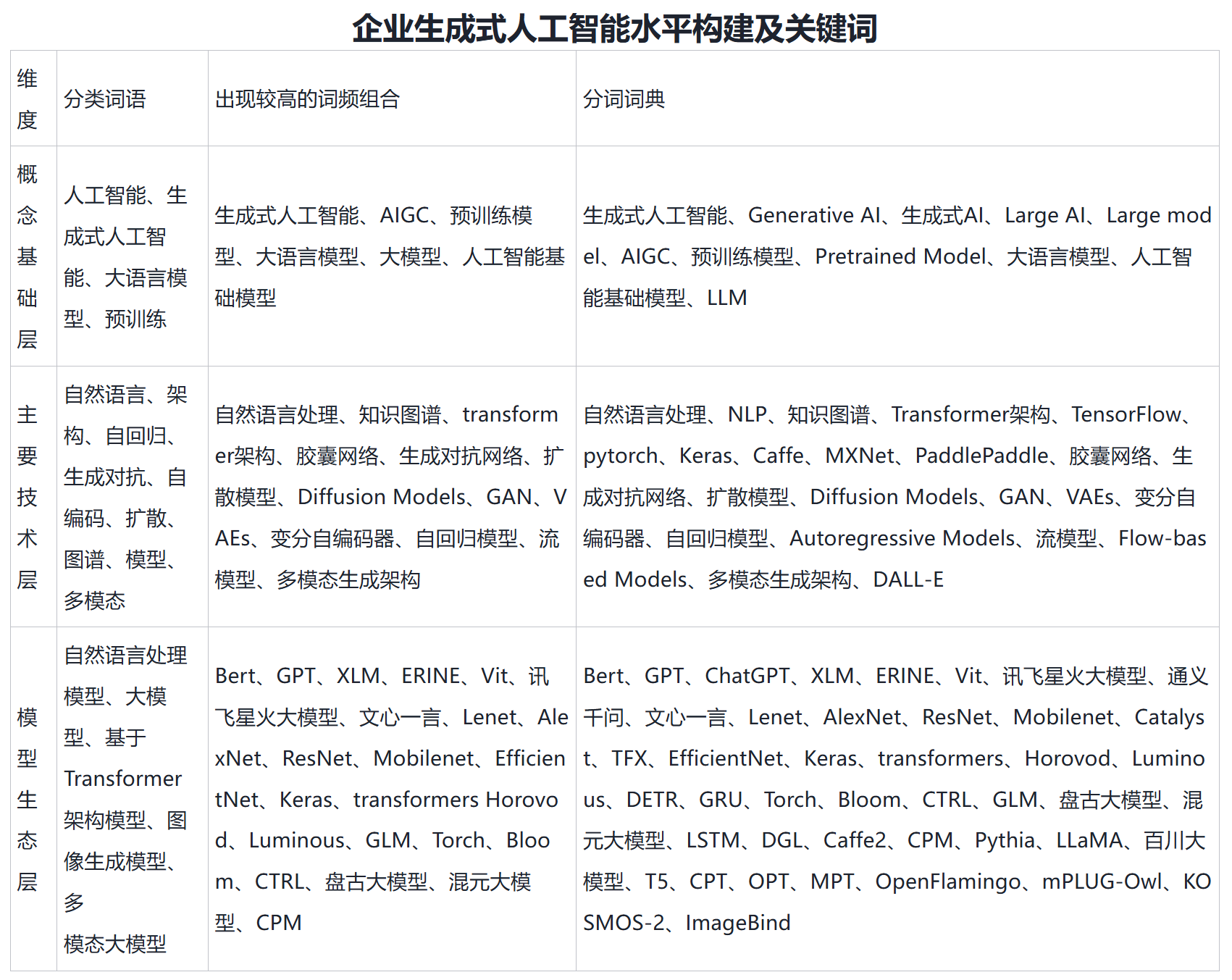
| 生成式人工智能水平 | 生成式人工智能词频总数 | 概念基础层 |
| 主要技术层 | 模型生态层 | 生成式人工智能 |
| Generative | AI | 生成式AI |
| Large | AI | Large |
| model | AIGC | 预训练模型 |
| Pretrained | Model | 大语言模型 |
| 人工智能基础模型 | LLM | 自然语言处理 |
| NLP | 知识图谱 | Transformer架构 |
| TensorFlow | pytorch | Keras |
| Caffe | MXNet | PaddlePaddle |
| 胶囊网络 | 生成对抗网络 | 扩散模型 |
| Diffusion | Models | GAN |
| VAEs | 变分自编码器 | 自回归模型 |
| Autoregressive | Models | 流模型 |
| Flow-based | Models | 多模态生成架构 |
| DALL-E | Bert | GPT |
| ChatGPT | XLM | ERINE |
| Vit | 讯飞星火大模型 | 通义千问 |
| 文心一言 | Lenet | AlexNet |
| ResNet | Mobilenet | Catalyst |
| TFX | EfficientNet | transformers |
| Horovod | Luminous | DETR |
| GRU | Torch | Bloom |
| CTRL | GLM | 盘古大模型 |
| 混元大模型 | LSTM | DGL |
| Caffe2 | CPM | Pythia |
| LLaMA | 百川大模型 | T5 |
| CPT | OPT | MPT |
| OpenFlamingo | mPLUG-Owl | KOSMOS-2 |
| ImageBind |
企业生成式人工智能水平构建及关键词
生成式人工智能词频统计-各年企业数量
生成式人工智能词频统计数据-Excel版
生成式人工智能词频统计数据-Stata版
注:该数据为高级会员-附赠数据,可在底部领取数据
该数据需要高级会员以上的权限,
请先登录您的账号: 点击登录